The Artist’s Machine
Computer-generated publication
Hardcover, 88 pages
2018
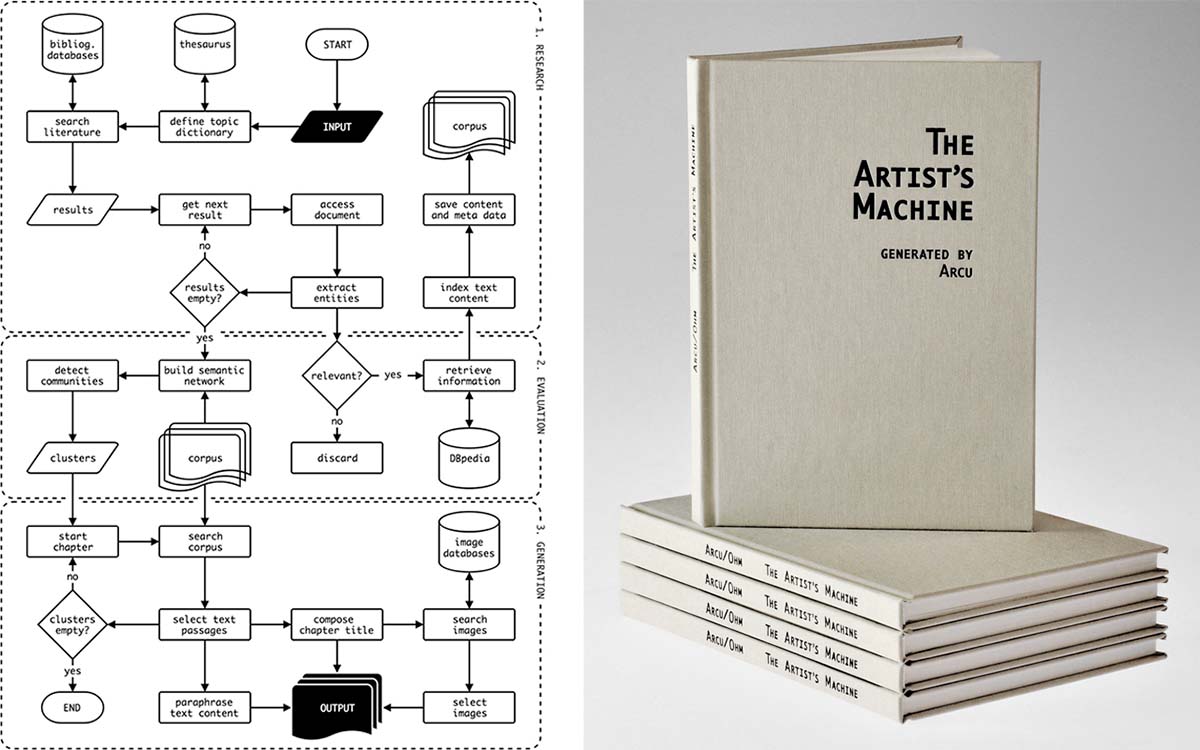
The Artist’s Machine is a computational research project with the outcome of a publication, generated by an algorithm called ARCU. From researching topic-relevant literature, detecting semantic structures in hundreds of papers and books, to finally generating a publication with illustrations and paraphrased text citations, every step in the process has been performed automatically – initiated by a simple research phrase that was given as input.
The main focus of this project is to develop a method for computational text curation and automated research, an experimental artistic use case for established Machine Learning services, search engines and databases.
Please note that this method has been elaborated in an applied experimental process. The algorithm can be considered as a proof of concept and a first goal-driven attempt to experiment with automated research and computational curation. Read more…
Download the PDF version here (CC-By Attribution 4.0 International). If you wish to purchase a physical copy of the book, please drop me an email.
Resources
Application Programming Interfaces
Cloud Natural Language API by Google Cloud Platform. https://cloud.google.com/natural-language/ (accessed from August to December 2017)
Cloud Translation API by Google Cloud Platform. https://cloud.google.com/translate/ (accessed January 2018)
Natural Language Understanding (API) by IBM Watson. https://www.ibm.com/watson/developercloud/natural-language- understanding/api/v1/ (accessed from August to December 2017)
Cloud Vision API by Google Cloud Platform. https://cloud.google.com/vision/ (accessed January 2018)
Databases
CompArt daDA: Digital art database. http://dada.compart-bremen.de/ (accessed January 2018)
Crossref: Bibliographic database. https://api.crossref.org/ (accessed from August to September 2017)
DBpedia: Semantic web database from Wikipedia. Dataset version 2016-04. http://dbpedia.org (accessed from September to October 2017)
Google Scholar: Bibliographic database. https://scholar.google.com/ (accessed from August to September 2017)
Media Art Net: Media art database. http://www.medienkunstnetz.de/ (accessed January 2018)
Thesaurus.com: Thesaurus, dictionary. http://www.thesaurus.com/ (accessed August 2017)
Wikimedia Commons: Media repository. https://commons.wikimedia.org/ (accessed January 2018)
Software and Tools
Gephi: Graph Visualization and Manipulation software. Version 0.9.2 for Mac OS. https://gephi.org
Google-api-python-client: Google API Client Library for Python. Version 1.6.3. http://github.com/google/google-api-python-client/
Google-cloud: Google Cloud Client Library for Python. Version 0.32.0. https://github.com/GoogleCloudPlatform/google-cloud-python
Habanero: Low Level Client for Crossref Search API. Version 0.6.0. https://github.com/sckott/habanero
NetworkX: Python package for creating and manipulating graphs and networks. Version 2.0. http://networkx.github.io
NLTK: Natural Language Toolkit. Version 3.2.4. http://nltk.org
Pdfminer3k: PDF parser and analyzer. Version 1.3.1. https://github.com/jaepil/pdfminer3k
PyDictionary: Python Module to get meanings, translations, synonyms and antonyms of words. Version 1.5.2. http://github.com/geekpradd/PyDictionary
Python: Python Language Reference. Version 3.5.2. http://www.python.org
SPARQLWrapper: SPARQL Endpoint interface to Python. Version 1.8.0. http://rdflib.github.io/sparqlwrapper
Watson-developer-cloud: Client library to use the IBM Watson Services. Version 0.26.0. https://github.com/watson-developer-cloud/python-sdk
Additional information
The main focus of this project was to develop a method to computationally write a graduation thesis. I want to stress that thereby, this is not an independent software or tool for ghostwriting, but an algorithm that simulates the human procedure of creating a comparative scientific work on a given topic. Starting with researching, right through to generating the final thesis, every step consists of automated processes.
During the research process, the algorithm collected 332 publications providing a corpus of 15 MB in plain text. From this corpus, 6.500 unique entities including 2.700 persons were extracted, building a semantic network with 40.000 connections.
The long-term goal of this project is to establish an artificial curator. As a first step, this expert system needs to become an actual expert in its specialized field of machine generated art. Therefore, I find it essential for the program to be initially concerned with the theoretical background and historical context of its subject.
While algorithmic translation from one language into another, speech synthesis, and speech recognition are quite advanced technologies nowadays, using language to express thoughts or ideas is a highly complex human ability, which machines so far fail to simulate. Hence, my contribution can be considered as a workaround, that consists of a combination of my own rule-based program code and the inclusion of external Machine Learning models. These models and off-the-shelf algorithms are mainly designed for industrial purposes, such as Marketing Research or Data Extraction. But I also integrated methods inspired by Data Mining and Network Analysis techniques. While the single components of my program are largely established practices in science and industry, their novel combination and unconventional use provides the foundation of my artistic approach.
Dealing with the crucial issue of decision-making in computer systems is another workaround in this project. I consider the algorithm to be the author of the work. For this reason, I step in as the human editor of the final publication. The topic is given to the program as input and triggers the research process in which relevant literature is searched and collected if possible. In some cases, the program asks for human help, for example, when a publication is not accessible. Later, when generating the thesis’ content, the algorithm provides several versions to choose from. By applying this method, randomness in the decision process can be minimized, as a qualified evaluation of its own output must be first learned by the program in a long-running process under human supervision. The practice of selecting a specific version or demanding a rewrite still comes within the relationship between the author and its editor. Likewise, mistakes such as wrong spelling or formatting, which can occur in converting PDF documents to text files automatically, are corrected accordingly.
Please note, that this method has been elaborated in an applied experimental process. The algorithm can be considered as a proof of concept and is therefore a first goal-driven attempt, to automate a strictly human domain.