fruit-SALAD

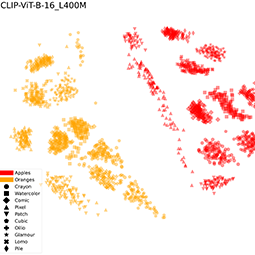
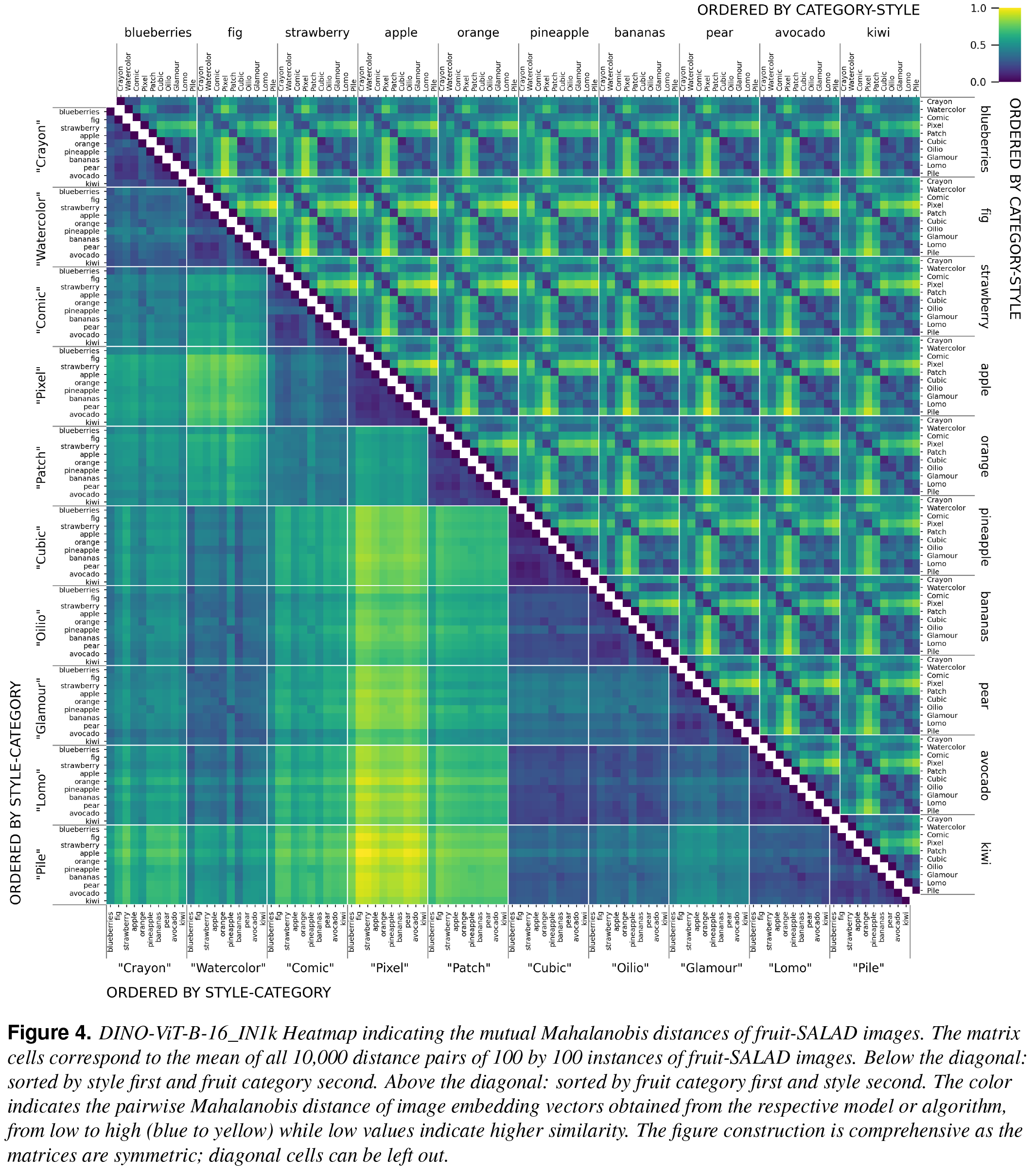
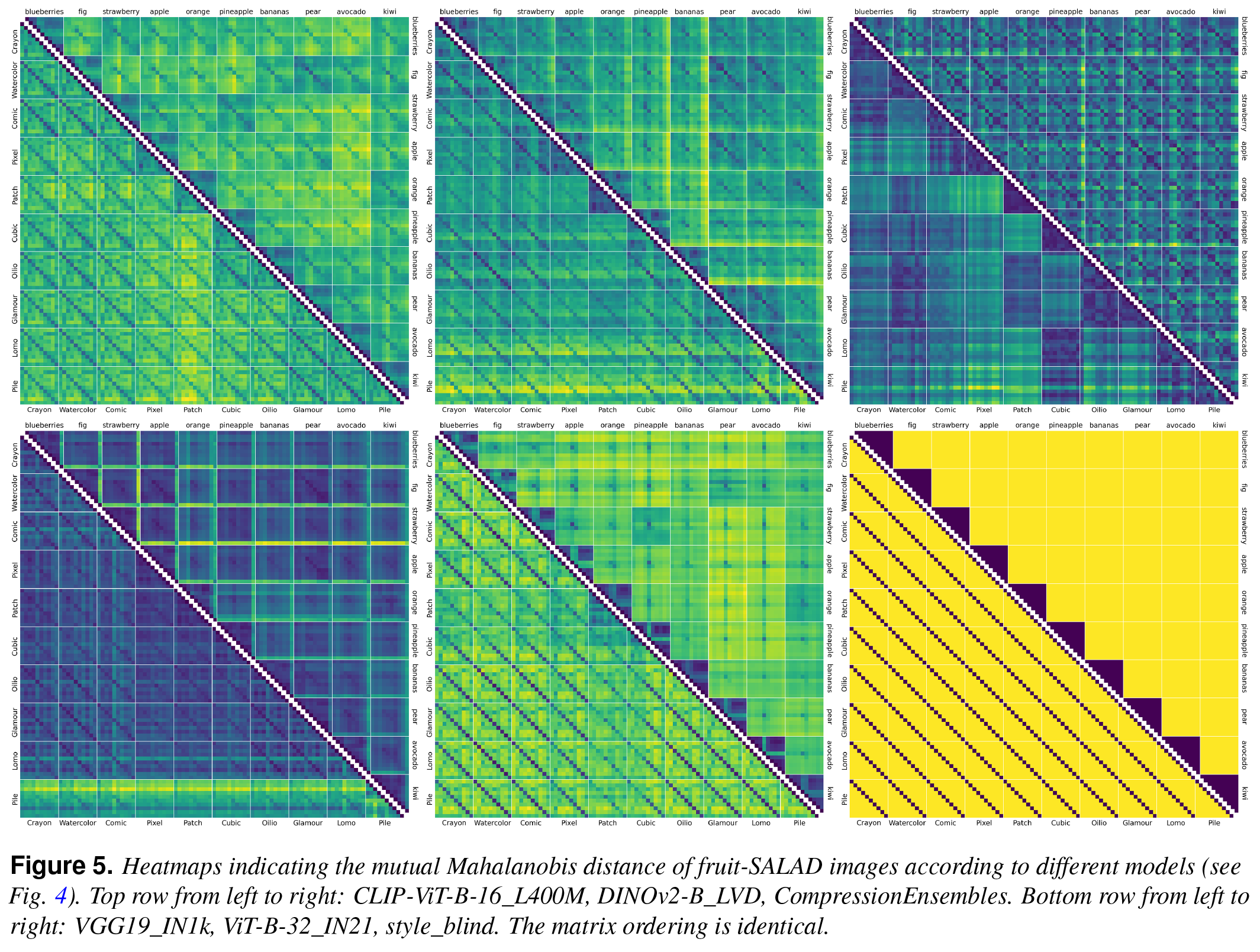
fruit-SALAD is a synthetic image dataset with 10,000 generated images of fruit depictions. This combined semantic category and style benchmark comprises 100 instances each of 10 easily recognizable fruit categories and 10 easy distinguishable styles.
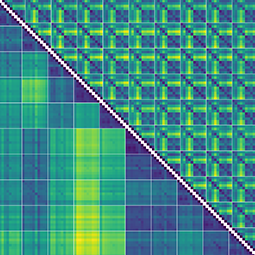
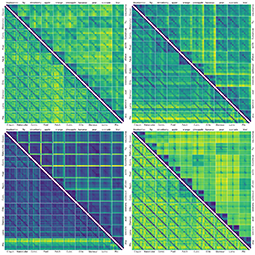
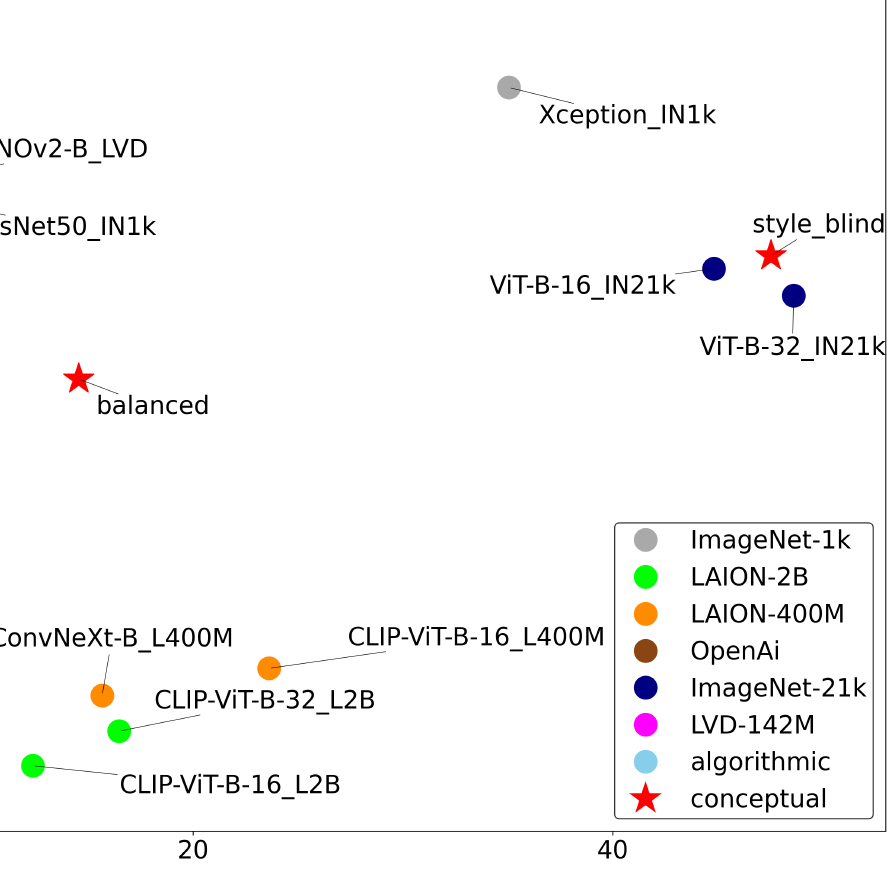
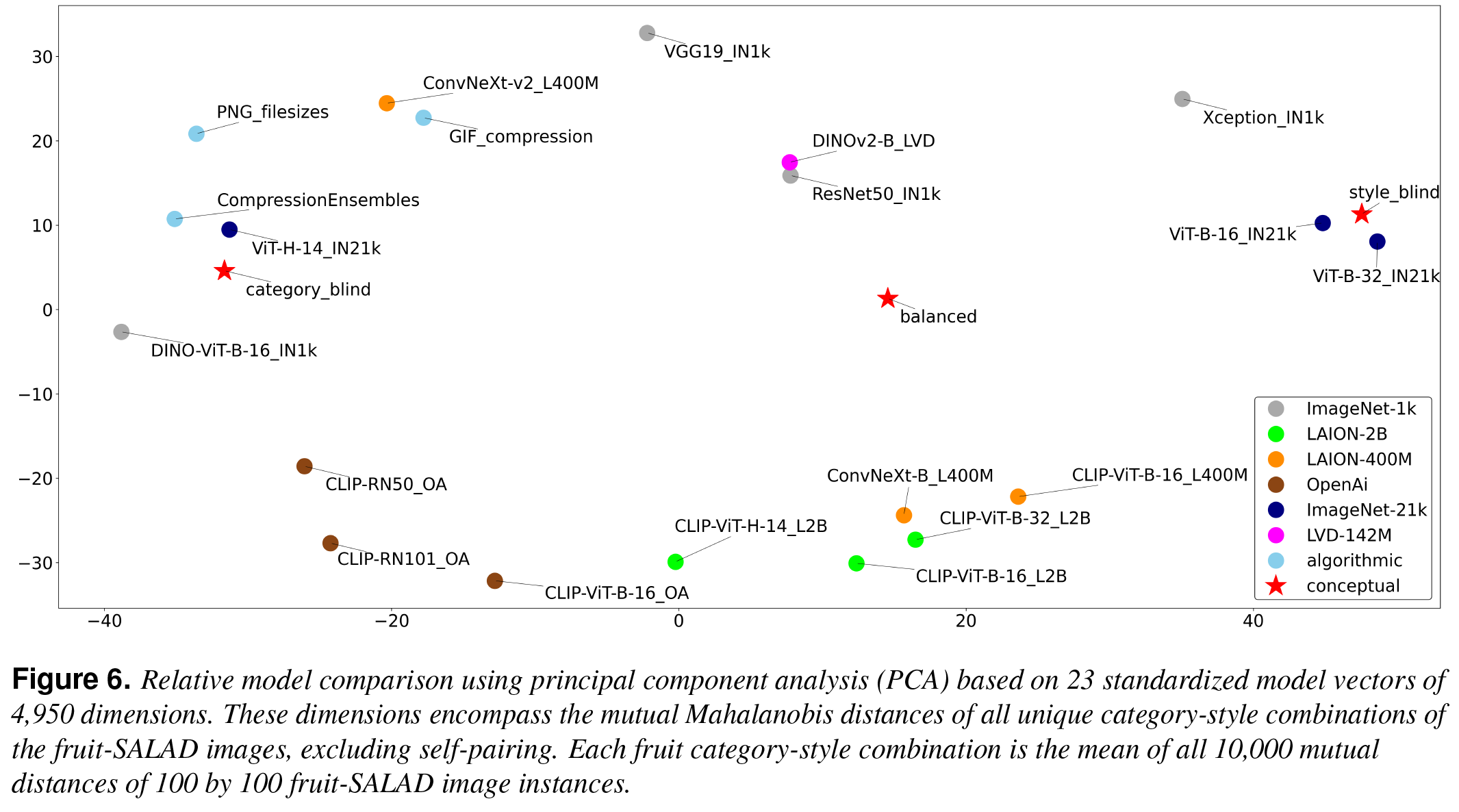
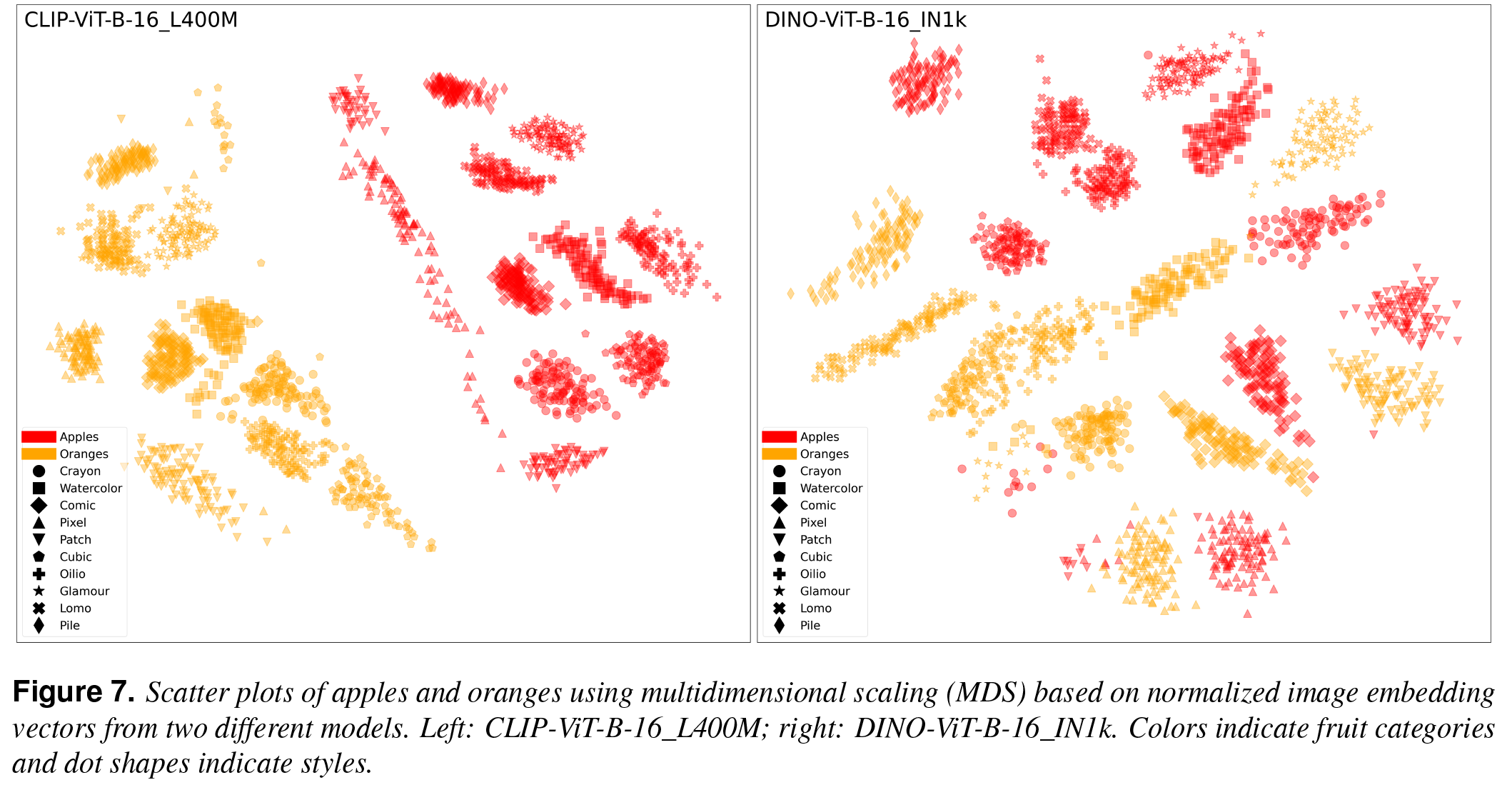
The carefully designed Style Aligned Artwork Dataset (SALAD) provides a controlled and balanced platform for the comparative analysis of similarity perception of different computational models. The SALAD framework allows the comparison of how these models perform semantic category and style recognition tasks, going beyond the level of anecdotal knowledge, making them robustly quantifiable and qualitatively interpretable.
We used Stable Diffusion XL and StyleAligned to create the fruit-SALAD by carefully crafting text prompts and overseing the image generation process.
Links
🍎 Project page
📄 Research paper
🕹️ Interactive tool
💽 Dataset
💾 Code
Abstract
The notion of visual similarity is essential for computer vision, and in applications and studies revolving around vector embeddings of images. However, the scarcity of benchmark datasets poses a significant hurdle in exploring how these models perceive similarity. Here we introduce Style Aligned Artwork Datasets (SALADs), and an example of fruit-SALAD with 10,000 images of fruit depictions. This combined semantic category and style benchmark comprises 100 instances each of 10 easy-to-recognize fruit categories, across 10 easy distinguishable styles. Leveraging a systematic pipeline of generative image synthesis, this visually diverse yet balanced benchmark demonstrates salient differences in semantic category and style similarity weights across various computational models, including machine learning models, feature extraction algorithms, and complexity measures, as well as conceptual models for reference. This meticulously designed dataset offers a controlled and balanced platform for the comparative analysis of similarity perception. The SALAD framework allows the comparison of how these models perform semantic category and style recognition task to go beyond the level of anecdotal knowledge, making it robustly quantifiable and qualitatively interpretable.
Figures
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Co-Authors
Andres Karjus, Mikhail Tamm, Maximilian Schich
Acknowledgements
All authors were supported by the CUDAN ERA Chair project for Cultural Data Analytics, funded through the European Union’s Horizon 2020 research and innovation program (Grant No. 810961).